
La IA no es mágica. Las herramientas que generar ensayos o Videos hiperrealistas De simples indicaciones del usuario solo pueden hacerlo porque han sido entrenados en masivo Conjuntos de datos. Esos datos, por supuesto, deben provenir de algún lugar, y que en algún lugar a menudo son las cosas en Internet que han sido hechas y escritas por personas.
Internet es una gran fuente de datos e información. A partir del año pasado, La web contenía 149 zettabytes de datos. Eso es 149 millones de petabytes, o 1.49 billones de terabytes, o 149 billones de gigabytes, también conocidos como lote. Tal colectivo de datos textuales, de imagen, visuales y basados en audio es irresistible para las compañías de IA que necesitan más datos que nunca para seguir creciendo y mejorar sus modelos.
Entonces, los bots de IA raspe la web en todo el mundo, aumentando todos y cada uno de los datos que puedan para mejorar sus redes neuronales. Algunas compañías, al ver el potencial comercial, firmaron acuerdos para vender sus datos a compañías de inteligencia artificial, incluidas compañías como Reddit, la prensa Associationy Vox Media. Las compañías de IA no necesariamente solicitan permiso antes de raspar datos en Internet y, como tales, muchas compañías han adoptado el enfoque opuesto, lanzando demandas contra compañías como OpenAi, Google y Anthrope. (Divulgación: la empresa matriz de Lifehacker, Ziff Davis, presentó una demanda contra Openai en abril, alegando que infringió los derechos de autor de Ziff Davis en la capacitación y la operación de sus sistemas de IA).
Esas demandas probablemente no están ralentizando las máquinas de vacío AI. De hecho, las máquinas necesitan desesperadamente más datos: El año pasadoLos investigadores encontraron que los modelos de IA se estaban quedando sin datos necesarios para continuar con la tasa de crecimiento actual. Algunas proyecciones vieron que la pista se dio en algún momento en 2028, lo que, si es cierto, solo le quedan unos años a las compañías de IA para que raspen la web para obtener datos. Mientras buscarán otras fuentes de datos, como acuerdos oficiales o datos sintéticos (datos producidos por Ai), necesitan Internet más que nunca.
Si tiene alguna presencia en Internet, existe una buena posibilidad de que sus datos sean absorbidos por estos bots de IA. Es escabullido, pero también es lo que podía los chatbots que muchos de nosotros hemos comenzado a usar en los últimos dos años y medio.
La web no se rinde sin pelea
Pero solo porque la situación es un poco grave para Internet en general, eso no significa que se rinda por completo. Por el contrario, hay una verdadera oposición a este tipo de práctica, especialmente cuando va tras el pequeño.
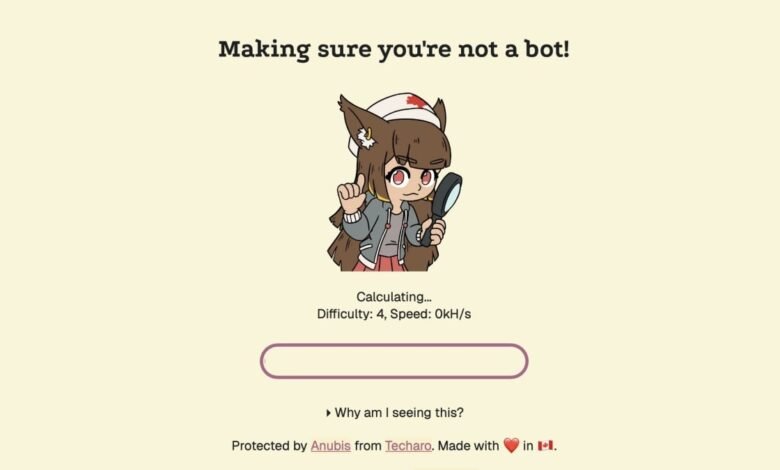
En la verdadera moda de David y Goliat, un desarrollador web se ha encargado de construir una herramienta para que los desarrolladores web impidan que los bots de IA raspen sus sitios para los datos de capacitación. La herramienta, AnubisLanzado a principios de este año, y se ha descargado más de 200,000 veces.
Anubis es la creación de Xe IASO, un desarrollador con sede en Ottawa, CA. Según lo informado por 404 MediaIASO comenzó a Anubis después de que descubrió un bot de Amazon haciendo clic en cada enlace de su servidor Git. Después de decidir contra derribar el servidor GIT por completo, experimentó con algunas tácticas diferentes antes de descubrir una forma de bloquear estos bots por completo: un «uncaptcha», como lo llama OASO.
¿Qué piensas hasta ahora?
Así es como funciona: cuando se ejecuta ANUBIS en su sitio, el programa verifica que un nuevo visitante es en realidad un humano al hacer que el navegador ejecute matemáticas criptográficas con JavaScript. Según 404 Media, la mayoría de los navegadores desde 2022 pueden pasar esta prueba, ya que estos navegadores tienen herramientas incorporadas para ejecutar este tipo de JavaScript. Los bots, por otro lado, generalmente deben codificarse para ejecutar estas matemáticas criptográficas, que serían demasiado exigentes para implementar en todos los rasguños de bots en masa. Como tal, IASO ha descubierto una forma inteligente de verificar los navegadores a través de una prueba que estos navegadores pasan en su sueño digital, mientras que bloquean los bots cuyos desarrolladores no pueden pagar la potencia de procesamiento requerida para pasar la prueba.
Esto no es algo en lo que el surfista web general necesita pensar. En cambio, Anubis está hecho para las personas que dirigen sitios web y servidores propios. Hasta ese momento, la herramienta es totalmente gratuita y de código abierto, y está en desarrollo continuo. IASO le dice a 404 Media que, si bien no tiene los recursos para trabajar en Anubis a tiempo completo, planea actualizar la herramienta con nuevas funciones. Eso incluye una nueva prueba que no empuja tanto la CPU del usuario final, así como una que no depende de JavaScript, ya que algunos usuarios deshabilitan JavaScript como una medida de privacidad.
Si está interesado en ejecutar ANUBIS en su propio servidor, puede encontrar instrucciones detalladas para hacerlo en la página de Github de IASO. Tú también puedes Pon a prueba tu propio navegador Para asegurarse de que no sea un bot.
IASO no es el único en la web que lucha contra los rastreadores de IA. Cloudflare, por ejemplo, es Bloqueo de rastreadores de IA por defecto a partir de este mesy también permitirá a los clientes cobrar a las compañías de IA que desean cosechar los datos en sus sitios. Quizás a medida que se vuelva más fácil evitar que las empresas de IA raspen abiertamente la web, estas compañías reducirán sus esfuerzos, o, al menos, ofrecerán a los propietarios de sitios más a cambio de sus datos.
Espero que me encuentre más sitios web que inicialmente se cargan con la pantalla de Splash de Anubis. Si hago clic en un enlace y me presentan el mensaje «Asegurarme de que no sea un bot», sabré que el sitio ha bloqueado con éxito estos rastreadores de IA. Durante un tiempo allí, la máquina AI se sintió imparable. Ahora, parece que hay algo que podemos hacer al menos ponerlo en control.



